How Tesla’s Computer Vision Approach to Autonomous Driving Built an Unassailable Lead in Full Self Driving

Written by Dheepan Ramanan (@dheepan_ramanan), Data Scientist and Ivan Kopas (@ivan_kopas), Machine Learning Engineer
Last Friday ARK Invest released a new price target for Tesla as well as an updated, open-source model. The scale of autonomous ride hailing networks and ARK’s estimate for Tesla’s dominance emerged as the most contentious elements in the model. These components contribute nearly 50% of ARK’s $3k 2025 price target. On twitter there has been considerable debate on the size of the Robotaxi market and Tesla’s lead in autonomous driving, questioning whether Tesla’s Full Self Driving (FSD) approach can be reverse-engineered and replicated by the competitors.
For example Gary Black, a noted Tesla bull and distinguished investor has doubts around the long-term advantage to Tesla’s approach to autonomous driving.
As practitioners of deep learning who have built multiple production ML workloads for Fortune 500 companies, we strongly disagree. In our view, the “race” is almost academic in nature . In this post, tailored to a non-technical audience, we will explain how Tesla has already won autonomy by taking a strategic computer vision (CV) approach that’s generalized, low-cost and highly scalable. Similar to the long and currently still ongoing struggle of the legacy automakers to replicate or reverse-engineer Tesla’s system for Over-The-Air (OTA) Updates, we strongly believe that replicating Tesla’s autonomous driving feature will prove to be orders of magnitude more challenging and, as a result, extremely unlikely.
How is Tesla’s approach to autonomous driving different?
Superficially, Tesla’s approach to autonomy may seem similar to other autonomous driving vendors, like Waymo, Cruise and Baidu. For instance, in Chandler, Arizona, both Waymo and Tesla cars can take a passenger from point A to point B autonomously. However, the differences become stark once we leave Chandler, AZ, and place these cars in any new location. The Waymo vehicle loses all self driving capability whereas the Tesla car may require a manual intervention but will, in general, still drive from point A to point B safely. This outcome is due to Tesla’s differentiated approach to autonomous driving which uses CV.
In general, there are currently 3 very distinct approaches to solving autonomous driving:
City-infrastructure modernization with sensors. In this scenario, various sensors are built into roads, traffic lights and road signs to communicate with autonomous cars and provide guard-rails for the cars to keep them safe. This is the approach that Baidu takes, but is unlikely to be replicated outside of China. This approach requires massive investments in new city infrastructure, it will not be scalable to most countries in the world and, for that reason, it will not be discussed further in this post.
LiDAR - The approach relying on the expensive equipment for “scanning” the environment and building high-definition maps for the cars to follow. This approach is currently followed by Google’s Waymo and GM’s Cruise (note these companies also apply CV, but not as the entirety of their FSD system).
Computer Vision - The approach relying purely on the Artificial Neural Networks (ANNs) to help the car become self-aware of the environment, even if it has never seen it before. This approach is used by Tesla, comma.ai and a few other smaller players.
Why is Computer Vision (using neural networks) superior to LiDAR?
Tesla is the only electric vehicle manufacturer developing autonomy to bet completely on computer vision instead of a LiDAR based approach. LiDAR stands for “light detection and ranging” and is essentially sonar using pulse laser waves to map distance between objects and build high-definition maps of the area. A simple analogy can illustrate the conceptual difference between Computer Vision and LiDAR. Imagine two students, where one is just cramming and memorizing the content (LiDAR), while the other one is trying to really understand the material and truly learn it (Tesla FSD). The student that learned the material (Tesla FSD) will be able to answer the exam questions correctly, even if the questions on the exam are swapped, the questions are rephrased, or new components are added to the questions, while the student that memorized the content (LiDAR) will likely fail the exam.
LiDAR is highly accurate and, combined with predefined maps, can create autonomous driving vehicles. However, there are major drawbacks to this approach.
Cost of equipment - Although LiDAR providers such as Luminar are working to lower the costs of LiDAR devices, currently this hardware is more expensive than consumer grade cameras.
Scalability/Adaptability - since LiDAR based approaches rely on pre-mapping every area, this makes them brittle. Only high-quality mapped roads can be driven on safely. Mapping out new areas is a costly and time-consuming per-requisite task that all companies utilizing LiDAR will have. Any changes to city infrastructure will need to be updated on high-definition maps used by autonomous vehicles to keep passengers safe. This requires continuous coordination between autonomy providers and city officials.
Transferability - Although LiDAR is good for object detection (eg, this is a car) it is not effective for recognition tasks (eg reading a stop sign).
These drawbacks are well documented, so why is it that Tesla is the only car manufacturer to focus on computer vision versus LiDAR? Three major factors come to mind:
Sunk Cost Fallacy
First-Principles Thinking
Tesla’s Data Snowball
Sunk Cost Fallacy- And How Convolutional Neural Nets Changed the World
When we examined the founding of LiDAR focused companies in the autonomous space, we noticed a trend.

2012 was a landmark year for neural networks. That year Alexnet, a deep learning convolutional neural network (CNN) won the ImageNet classification challenge by 10%. This was the first time that a deep CNN was applied to image classification. Although CNN’s existed previously, training deep networks at scale was impractical until the innovation of training on graphics processing units (GPUs). This breakthrough created a renaissance in neural network research and the following years saw steadily declining error rates in the ImageNet competition.

So why didn’t companies like Luminar, Cruise, and Waymo adjust to use a computer vision approach? Likely, there is an element of psychology at work. These companies hired experts in LiDAR before the exponential improvements in deep learning technology. Secondly, there is the capital allocation factor. Hardware intensive solutions like LiDAR require larger amounts of upfront capital investment and longer cycle times before results can be validated. To make a 180-degree turn towards computer vision required the engineering and executive teams of these companies to invalidate their own strategy. In many ways there are parallels to Intel’s decision to focus entirely on x86 chips as ARM chips steadily improved and eclipsed their performance in 2021. Tesla avoided this sunk-cost fallacy and used first principles thinking to focus on CV.
First-Principles Thinking
Tesla espouses a “First-Principles Thinking” approach to problem-solving. This methodology requires forgetting legacy constraints and conventional wisdom to solve a problem from the ground up. Tesla has stated that solving autonomy with Computer Vision is much more difficult than utilizing LiDAR, but it is the only approach that can scale quickly.
Another company that recognized the advantage of speed and scale of computer vision is Mobileye. Founded in 1999, Mobileye was the first autonomy company to focus on a 100% CV solution. Prior to 2016, Mobileye provided the hardware and software for Tesla’s Autopilot but has since gone to a CV with LiDAR augmented approach. Why has Mobileye changed their approach while Tesla maintains a 100% CV solution? In our opinion, it’s because Mobileye and other self-driving startups lack Tesla’s data snowball effect.
Tesla’s Data Snowball Creates Bigger, Better, More Accurate Models
“Getting wealthy is like rolling a snowball. It helps to start on top of a long hill—start early and try to roll that snowball for a very long time. It helps to live a long life.” - Charlie Munger
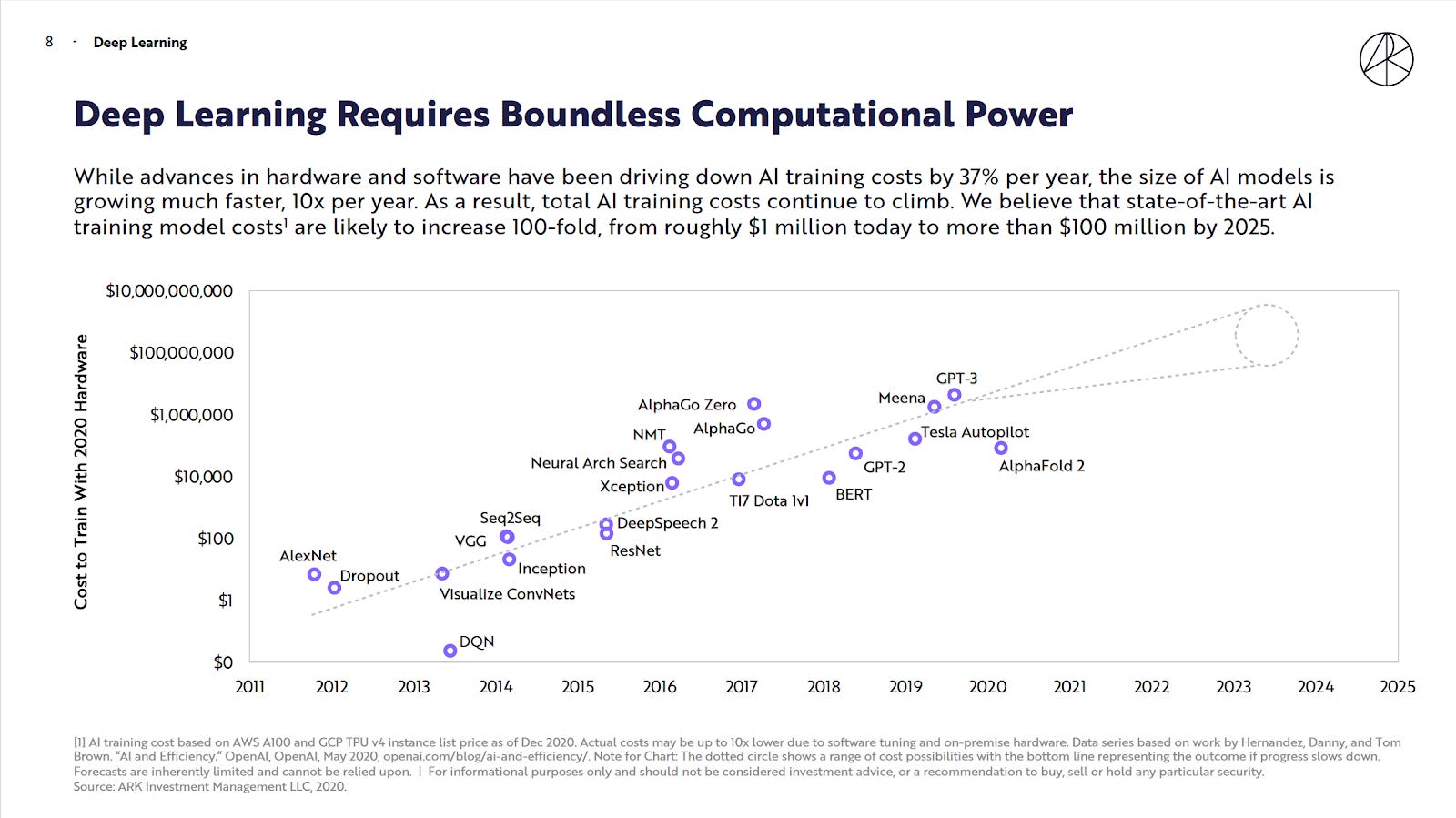
Mr. Munger’s quote about compound interest also applies to the benefits of data to deep learning. Simpler and shallow neural network models saturate their efficacy with lower amounts of data. Denser and deeper neural networks can approximate more but require exponentially more data. In practice, this means a data advantage creates a machine learning modelling advantage. Tesla is in a league of its own with data collection and data labeling, where the data labeling team at Tesla is an entire highly trained organization with a much larger head-count than their actual machine learning team of scientists and engineers. To illustrate the difference in scale, Waymo had roughly 20 million miles driven in 2019 compared to Tesla’s 3 billion. This 150,000% scale difference ensures that Tesla has an unsurpassed lead quantity and quality of data to train deep learning models.
In this hypothetical situation, Waymo may be able to develop computer vision models that perform at 90% or even 95% accuracy but achieving that several 9s-level performance (e.g. 99.99%) through vision is not practical with the size of their small fleet. This is why Mobileye is using LiDAR (combined with CV) and building 3-D maps of cities one city at a time. Without a fleet of autonomous data collecting robots to feed into ever increasingly large models, LiDAR is the best solution. But ultimately, this is limiting. Assembling high-definition maps city by city is an arduous, slow process and creates an inflexible system that cannot handle change.
This data advantage has already created breakthroughs for Tesla. For example, the FSD Beta shows surrounding cars, road signs and streets with 3-D depth. This is using traditional computer vision to create a 3-D depth of field similar to LiDAR systems. In future iterations of the FSD software, Tesla will move to a “4-D” version of the software that incorporates a time dimension. All of these additions require deeper, more complex neural networks that need data at a scale that other vendors cannot match.
Why Tesla’s Verticalized Computer Vision Approach Cannot Be Easily Copied
It should be evident by now why Tesla is unique in the self-driving space in using a computer vision-based approach and why Tesla’s data lead compounds advantages with artificial neural networks. In the last section, we will demonstrate why this “stack” is not easily transferable.
A neural network is not code in the traditional sense. It doesn’t rely on the traditional conditional if/else construct, but outputs a probability of a certain event occurrence. This set of probabilities are then fed into traditional code to generate the behavior of the entire system (this is the gist of Software 2.0). A neural network is nothing but a series of mathematical weights (numbers) and instructions for computational operations. This system only works with a set of inputs that is identical to what it was trained on and runs well only on the hardware it was designed to execute on.
A typical workflow for deploying deep learning models to an edge device (e.g. Vehicles):
Accumulate and label a large set of data, ensuring high accuracy of the labels
Train a large model consisting of one or more artificial neural networks, using self-supervised techniques (the model teaches itself).
Use this initial model to train on a set of supervised tasks that have labelled data (e.g. Stop Sign images)
Approximate this model to fit on a device (fit another model that achieves the same result but with less parameters/numbers)
Optimize the model to achieve maximum throughput on a given device
Deploy the model and monitor the feedback to verify online performance
If Volkswagen (VW), for example, was to copy all of the code and model weights in a Tesla with FSD, it wouldn’t get very far. To even achieve predictions from the system they would need to build all of the exact same camera and radar equipment in all of their vehicles. Secondly, without Tesla’s data they would be unable to retrain any of the models for improvements. If, for example, a new neural network architecture, that was more computationally efficient (e.g. Transformers), was introduced, without Tesla’s data collection they could not take advantage of it. If a new road sign for “No Autonomous Driving” cropped up, they could not train the copied system to respond to the change.
Secondly, within each of these steps Tesla has vertically integrated equipment, processes and code to maintain their autonomy lead:
Data collection through OTA updates. VW is going to do their first iteration of this with 3,000 cars (sometime soon).
A team of specialized data labellers to curate a massive dataset of images
A specialized supercomputer to train large neural networks efficiently (Dojo supercomputer).
A specialized hardware system, which Tesla built in-house, to improve neural network throughput when making predictions (inference).
Shadow-testing through silent inference, where the neural net is still making predictions while humans drive, but those predictions are not used to control the vehicle.
Even if conventional OEMs were to assemble the talent, tools, and code to build this today, they would be years behind Tesla’s computer vision approach. They simply haven’t collected the data to reconstruct Tesla’s models. These models cannot be reverse-engineered due to the black-box effect of all the data transformations that occur before the machine learning model is trained. As a result, many OEMS (like VW) have decided to outsource autonomy to a LiDAR based system (like Mobileye, Luminar, etc.) and hope that advancements in neural networks don’t occur too quickly.
We believe they are wrong. This period before the wide Tesla FSD beta release is the last window of uncertainty. When the majority of Tesla’s run the new FSD software, Tesla’s data snowball will further compound, turbocharging the flywheel of model improvement. This will lead to L5 autonomy sooner than many predict. In the next year, Tesla will likely be cemented as the autonomy leader.
Disclosure: Authors are both long Tesla shares.
This article seems to really miss the mark on predicting the future which is why autonomous systems are almost certain to fail if this is the very limited perspective taken by the average "engineer" with their head stuck in the clouds when the reality of expectations is so much broader. It's hard enough to assure over 30% of the general public that vaccines are safe when the data suggests that the proportion of population rejecting vaccines should be lower based on the expected rate of adverse outcomes. Just because the data suggests some rational outcome that doesn't mean you will get that outcome unless you take into account a multitude of other factors. Just imagine how the public will receive robot cars when they hear about a slew of fatal accidents even if ] we're talking small probabilities that they occur. And what if work as we know it is transformed by automation and AI? We're already seeing permanent WFH and subscriber based concepts proliferating. It seems highly plausible that the automotive industry will consolidate due to a substantial decline in vehicle ownership. Maybe we get L5 but the competitive landscape will be far different from what is depicted here and Tesla survives for very different reasons.
This article assumes that L5 autonomy is even possible or will ever be accepted by consumers as a necessary "feature". Imagine an L5 system that has been tested to 99.9% of scenarios and assume that 0.01% of scenarios can never be mitigated without human intervention (freak rain storm, snow storm, flying object/vehicle that cannot be avoided, sinkhole in road, failing to correctly interpret a cliff in poor weather, something the system has never experienced, etc. etc.) . Assuming 200 M vehicles at 200 driving days each you end up with 4 M failures. If we assume only 1% of those failures result in fatal accidents that's 40k fatalities related to L5 failures. Maybe my math is wrong or my expectations are flawed but just based on even more conservative versions of these numbers (like 10k fatalities) it seems highly unlikely that we can engineer enough public confidence in these systems "initially" given a certain minimum level of failure that cannot be mitigated. Logically, it would seem that given the rare nature of catastrophic scenarios, more exposure to these scenarios wouldn't help the system learn how to handle them either. It would just end up with PTSD and drive exceedingly cautiously around anything that remotely resembles a scenario in which it previously failed. Don't forget the arrogance of Boeing in engineering MCAS. You cannot entirely predicate success on the tech alone.
So to me the question is more how do you re-engineer the vehicle itself to withstand potential catastrophic circumstances that while low probability will be survivable or come up with better algorithms for how autonomous systems behave when dealing with unexpected circumstances (other than stopping in the middle of a road). Tesla should start with commercial autonomous systems like for bus drivers and semi truckers that have lower risk/publicity expectations, simpler cockpit environments, and make it work under some radical failure scenarios. Once you can get L5 broadly into that market then it will be far more widely accepted by retail consumers. As it is, you already have people being triggered by Teslas. If the engineers in charge don't proceed carefully they could just end up with another Google Glass or Boeing 737 Max.
are u idiot... waymo,cruise, can work anywhere in the world once they map area.. the main problem is weather.. and infrastructure to handle it.... example - suppose you drive from point A to point B ( 50 miles etc) if there is weather issue or snow , rain in road it need to handle no car in the world will handle it even human not able to drive in all weather conditions ... user safety is main concern ...you can make any product but if a product kill the human nobody will acecpt it... simple....